



Data Annotation
Data annotation is a process of representing or tagging data like images, texts, audio, and videos. For example, assigning labels to bulk data of fruits pictures so that they can differentiate from each other. Mostly, each picture contains one object.

Data Labeling
Data labeling is a process of identifying and adding more information and highlighting some regions of interest in a picture, text, audio, and video to assign a proper label to represent that highlighted part. Labeling can be descriptive, informative, identification, and grading. For example, when we have a picture that contains multiple fruits and we want to label each fruit.
Need for Data Annotation
As it is an era of Artificial Intelligence. So, everyone wants to know how AI works? AI has six branches which are Machine Learning, Deep Learning, Natural Language Processing, Robotics, Expert Systems, and Fuzzy Logic. To work with these branches we need data to feed as input to build an intelligence system. So, in each branch different types of learning are there but when we want to work with supervised learning, we need data with outputs to train the model. Here output means the label or description of that data to teach the rules to our training model.
Hence, the process of annotating, marking, labeling, and tagging data to feed the model is called data annotation. By doing this we can teach specifically to the training model which data is representing what. On the basis of rules, the training model can easily learn and can help us to predict unseen data in the future.
Role of Data Annotation in AI
There is an important role of data annotation in AI. As we know, all branches of AI are dependent on accurate data to learn and predict. Therefore, annotated data is like a dataset for the training of any AI model from which we want the model to extract features to learn and recognize. So, we use annotated data in the training of supervised learning models. We give annotated data and labels as input to the model. By doing this, we can specifically tell training models where the object is exactly placed, how much its region of interest, and what it is representing.
As mentioned, different types of data annotations so, we have to choose the best annotation type according to our data complexity. Because selecting the perfect annotation type will help us in marking accurate regions of interest. And it will help in the training of model to extract the features from the exact region of interest. By this, we can get the highest accuracy. And our model will not confuse, overfit and underfit because of different extra background pixels and outer region pixels of the object.
Also, we use different types of data to give input to models in training of supervised learning which we can't pass directly just without making it understandable for models. So, we do data annotations.
Data can be like:
- Images
- Audios
- Videos
Texts
Images
Images dataset consist of different types of pictures and quality. Some images have one object and some have multiple objects. And images dataset can be related to fruits, vegetables, faces, scenes, body parts, vehicles, animals’ recognition, etc. So, we annotate objects according to our needs and label them. Each label explains the object. Different styles of images dataset like binary class datasets, Multi-class single label datasets and multi-class multi-label datasets we prepare for training of the model. Thus, we use the best annotation technique to annotate our data.
Videos
Videos dataset consists of short video clips. Video is a recording of moving visual images. The one-second video consists of different numbers of images/frames. There are two ways to annotate video data. The first is to break videos into frames using a tool or coding and annotate some frames of every second video using annotate images techniques. The second is to upload a video dataset on any tool and annotate each video by specifying how many frames you want to annotate in each second. That tool will show you entered quantity of frames one by one and you can label that by using image annotation techniques too.Audios
Audios dataset consists of different types of audio clips like language, speaker demographics, dialects, mood, intent, emotion, and behavior. During annotation, we annotate and label different features of clips like timestamping, audio, and more also non-verbal instances like silence, breaths, and even background noise can be annotated for the training model to understand comprehensively.Texts
Annotating a text dataset means adding labels and meta-data to text, like semantics or sentiments. The annotated text helps the training model understand the natural language of humans. We use different ways to annotate text data. These are the various text annotations ways:- Semantic Annotation
- Intent Annotation
- Text Categorization
- Entity Annotation
- Named Entity Recognition
- Entity Linking
Different Tools use for Data Annotation and Labeling
Paid
Free
Different types of data annotation and use cases
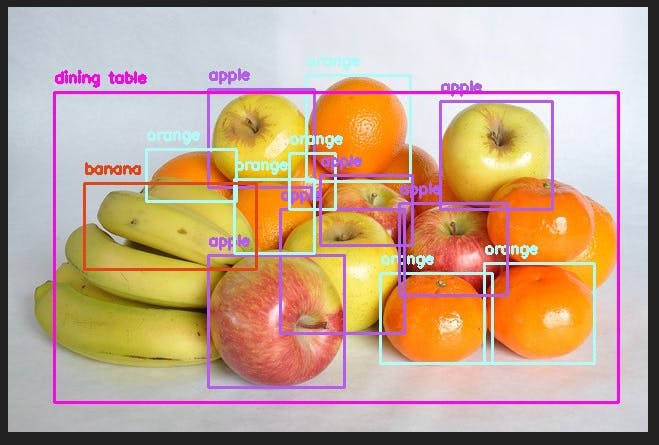
Bounding Boxes
In this type of annotation, we make the rectangular boxes around the region of an object to identify it in an image and to label it. Each bounding box produces x and y coordinates of a region and then we assign it a label/class. If there are multiple objects in a picture then we have to make multiple bounding boxes and have to assign labels or classes. The main purpose of this is to get the label of the object and location.
Use cases
For example, when we want to detect multiple food products in a grocery store, detect exterior vehicle damage, and want to detect multiple items in a picture.

Bounding Circle
In this type of annotation, we can draw a perfect circle around the object. When objects are perfectly circular, circle annotation might be really appropriate because it will save you a lot of time compared to having to draw round shapes by hand.
Use cases
For example, when we want to recognize the ball on the ground, a hole on the road, the round shape fruit, vegetable, etc.

Bounding Ellipse:
When the target objects are not perfectly circular but have uniform shapes, then the ellipse is perfect for the annotation. It saves time to annotate when objects are not perfectly round.
Use cases
When we want to annotate the eggs dataset, human faces dataset, etc.

Lines and Splines
In this type of annotation, we make the lines and splines to specify boundaries between objects in the image. It is commonly used when the boundary and edges of an object don't make any sense to recognize.
Use cases
For example, when we have to recognize the broken and double lanes on the road, recognize the conveyor system boundaries to place boxes in the center of the belt and in the warehouse to exactly set items in a row.

Polygonal Segmentation
In this type of annotation, we make polygons around the complex shape of images. So, we can easily mark the only region of an object and get the exact location in an image which will increase accuracy while in inbounding boxes we make rectangles that sometimes contain useless pixels.
Use cases
For example, when we want to annotate the irregular shapes of objects also it is useful in autonomous driving when we have to detect irregularly shaped sign boards, and logos, and locate cars.

Semantic Segmentation
In this type of annotation, we assign the class and color to each pixel or group of pixels to different types of objects in an image. It is a pixel wise annotation. Through this, we can only get the all-exact pixels of an object.
Use cases
For example, when we want to navigate the robot around one class region, scene understanding and specially in autonomous driving to make difference in between sidewalks, road grass and section of road.

3D Cuboids
In this type of annotation, we also mark the depth information of an object with height and length to predict the shape and volume by making the rectangle, circle and elliptical boxes around the region of an object to identify it in an image and to label it. It gives us 3D representation and values of the x, y, and z-axis.
Use cases
For example, we use this type of annotation in driverless cars to calculate the distance between objects.

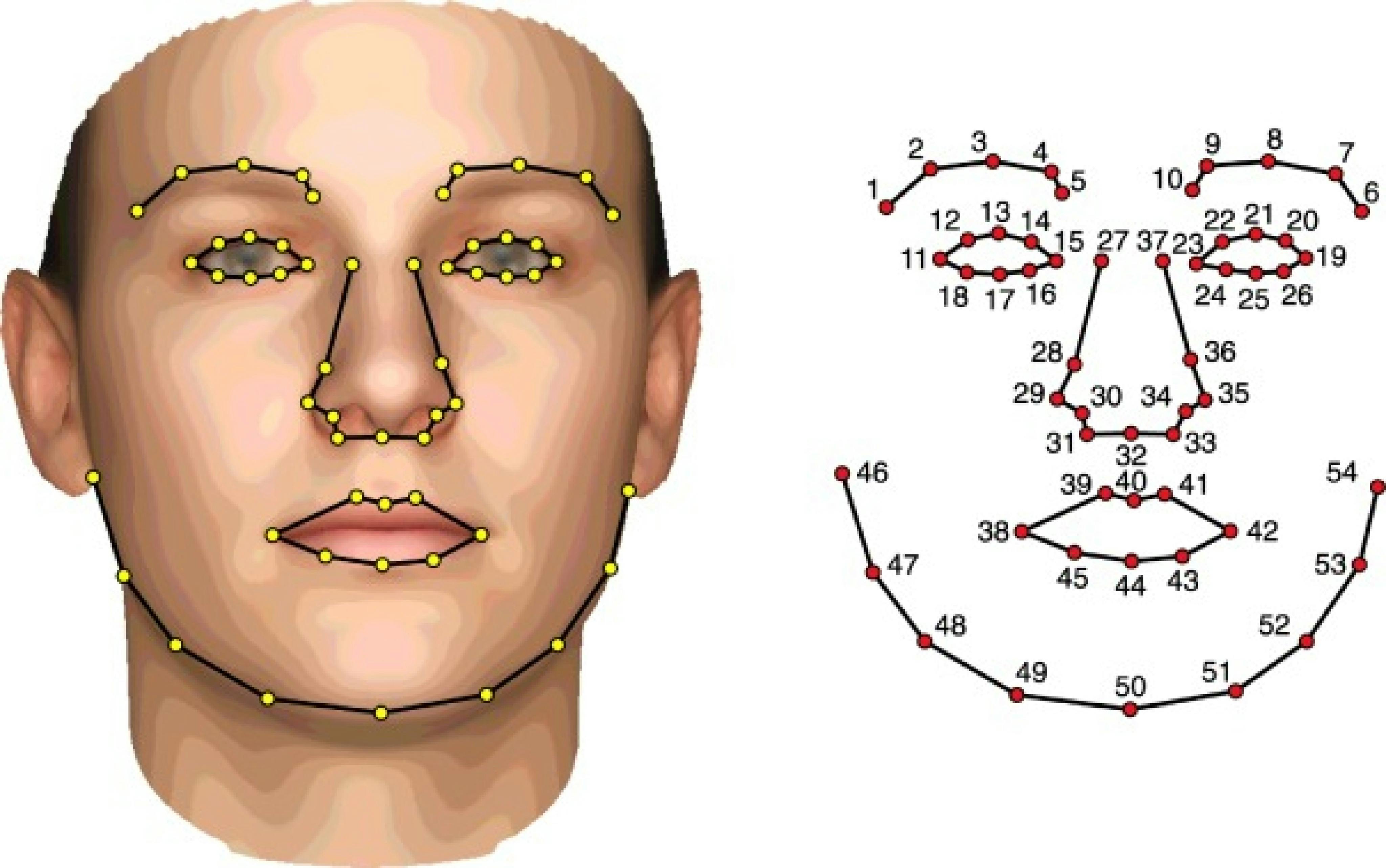
Landmark and Key-point
In this type of annotation, we make dots around the image to form a sort of outline. It is use when an object has different features to focus.
Use cases
For example, we use this type of annotation in face detection so, that it can exactly get the shape of lips, nose, ears, and eyes.
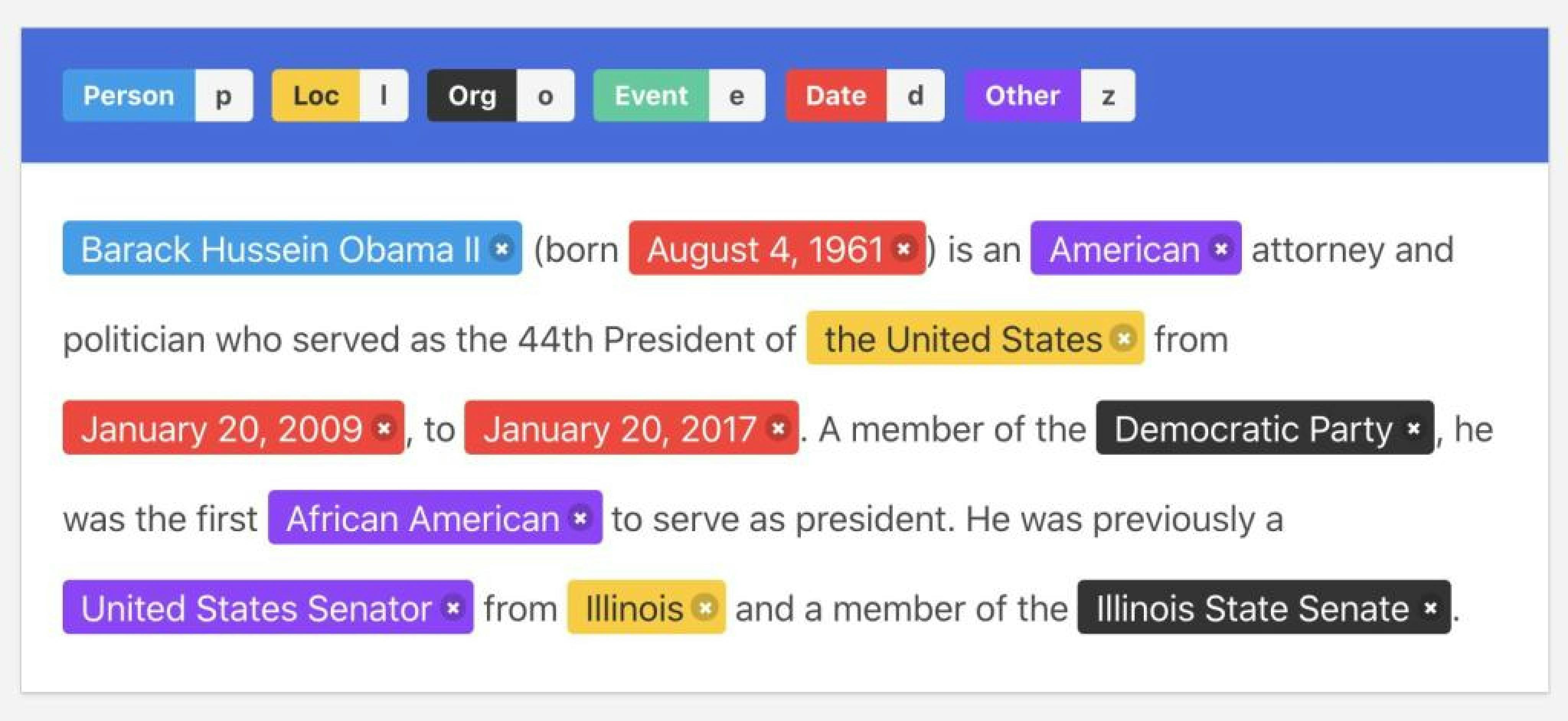
Entity Annotation
In this type of annotation, we mark some part of unstructured sentences and assign label to it. So, each sentence has multiple labels. Mostly we use this technique in-text annotation.
Use cases
For example, when we want to search for words based on their meaning such as location, name of the place, etc. Two types of entity annotation are:
Named Entity Recognition
In this, we annotate and labeled places, people, events, organizations, and more in each statement of text data.
Entity Linking
When those labels are linked to sentences, facts, phrases, or opinions that follow them.
Use cases
For example, when we want to create the relationship between the texts associated and the statement surrounding it.
Conclusion
In this article, I mentioned what data annotation or labeling is, what are its techniques and benefits and how we can use these techniques to annotate and label data for the training of Machine Learning models. Besides this, we have also listed the top tools used for annotating and labeling images. Thus, the process of labeling texts, images, and other objects help ML algorithms to improve the accuracy of the training model, data prediction and offer an ultimate user experience.